
You may remember us from such Oban optimization chronicles as "slashing queries per minute with centralized leadership", "minimizing data over the wire with notification compression", and "reducing database load with lazy batching". Well, we're back with a few more accounts for you.
Performance matters, particularly for a background job system so closely integrated with your application's database. That's why recent Oban Pro releases have focused extensively on optimization—to ensure Oban scales right along with your system as traffic increases.
Today, we'll present two recent Pro features designed to alleviate database bloat and dramatically reduce overall transactions.
Bundled Acking
Job fetching is optimized to retrieve multiple jobs with a single query. However, "acking", the process of updating a job after it finishes executing, requires a separate query for each job. That puts stress on an application's shared Ecto pool and can cause contention when there aren't enough connections to go around. The pool can only scale so far because database connections aren't free.
One alternative approach is to make acking async. During the one million jobs a minute benchmark we experimented with async acking, but found the loss of consistency guarantees unacceptable. Since then, the issue of excessive transactions hasn't changed, so we revisited the optimization with Pro's Smart engine.
Async Acking in the Smart Engine
Async acking alleviates pool contention and increases throughput by bundling calls together and flushing them with a single database call. Acks are recorded with a lock-free mechanism and flushed securely in a single transaction, along with the next fetch query. A system of retries and careful shutdown routines ensures acks are recorded to the database before shutdown, et voilà, async acking is as consistent as the synchronous version.
Comparing Queries Between Engines
The following chart (populated with this script) compares how many queries are required to
process a varying number of jobs using Oban's Basic engine and Pro's async Smart engine. The
concurrency limit is set to 20 for both engines:
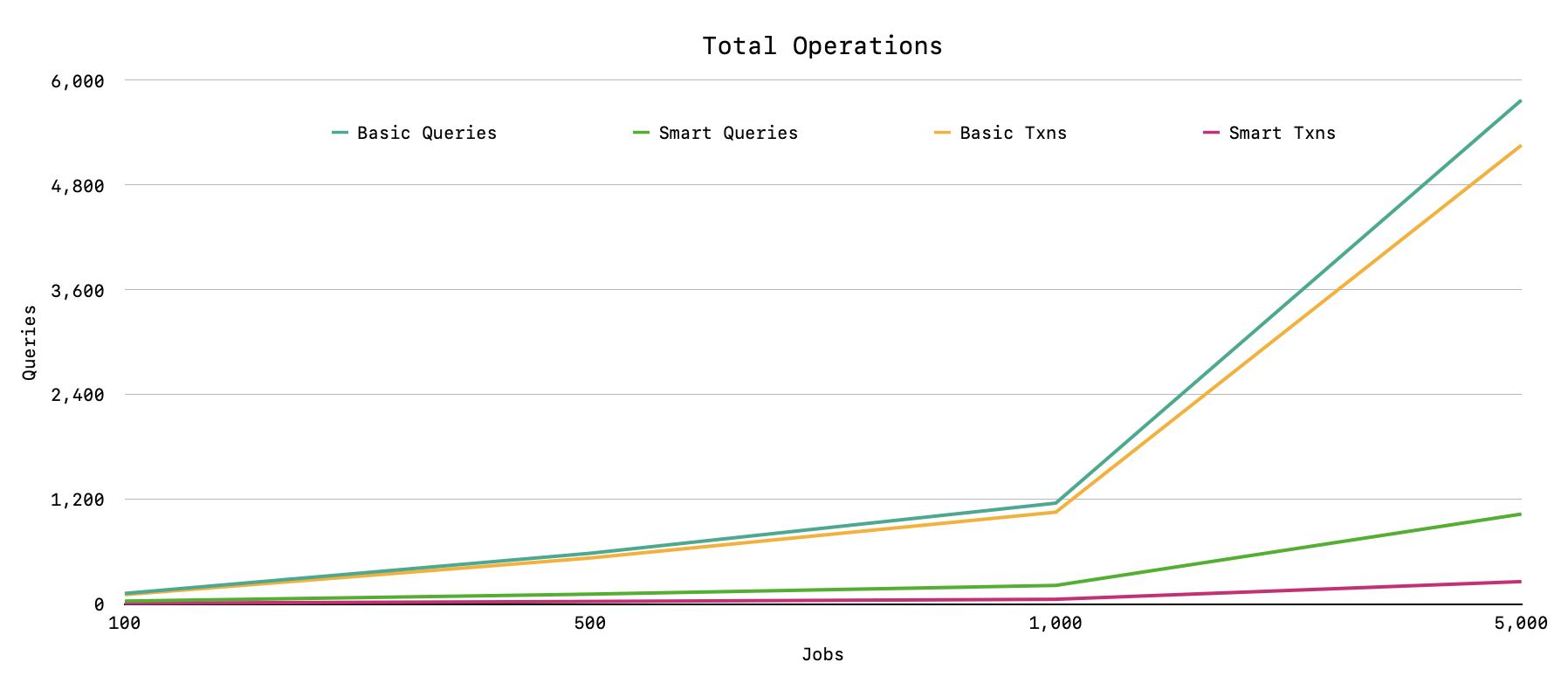
At 1,000 jobs the Basic engine uses 1,157 queries (1k acks and 157 fetches) across 1,053 transactions, while the Smart engine only uses 214 queries over 55 transactions, and the disparity grows from there. The higher a queue's throughput, and the higher the concurrency limit, the higher the reduction in queries.
Async acking works transparently, without any configuration changes, and it just shipped in Pro v1.3. Fewer queries, fewer transactions, and less pool contention with a seamless upgrade.
Table Partitioning
As is standard for any update-heavy Postgres workload, processing jobs at scale accumulates a lot of dead tuples, e.g. rows that were deleted or updated but not physically removed from the table. It's not until a CPU hungry vacuum process flags them as available for re-use that the rows are cleaned up—even then, they still occupy space on disk.
In contrast, table partitioning, where a table is broken into logical sub-tables, has tremendous maintenance advantages. Tables are smaller, vacuuming is faster, and there's less bloat after vacuuming. The best part—bulk deletion, aka pruning, is virtually instantaneous.
Partitioning the Jobs Table
Pro v1.2 shipped with support for partitioned tables managed by a DynamicPartitioner
plugin and its companion migration. The oban_jobs table is strategically partitioned by job
state and then sub-partitioned by date for cancelled, completed, and discarded states.
The DynamicPartitioner is then responsible for the daily maintenance of creating and deleting
new sub-partitions.
Frequent queries such as job fetching are faster for high-volume tables because they're scoped to smaller, active partitions. Also, since dropping a partition immediately reclaims storage space, pruning completely avoids the vacuum overhead from bulk deletes.
Benchmarking the Partitioned Table
A synthetic benchmark of 1m jobs a day for 7 days in Postgres 15 showed outstanding improvements. Partitioning faired better in every category.
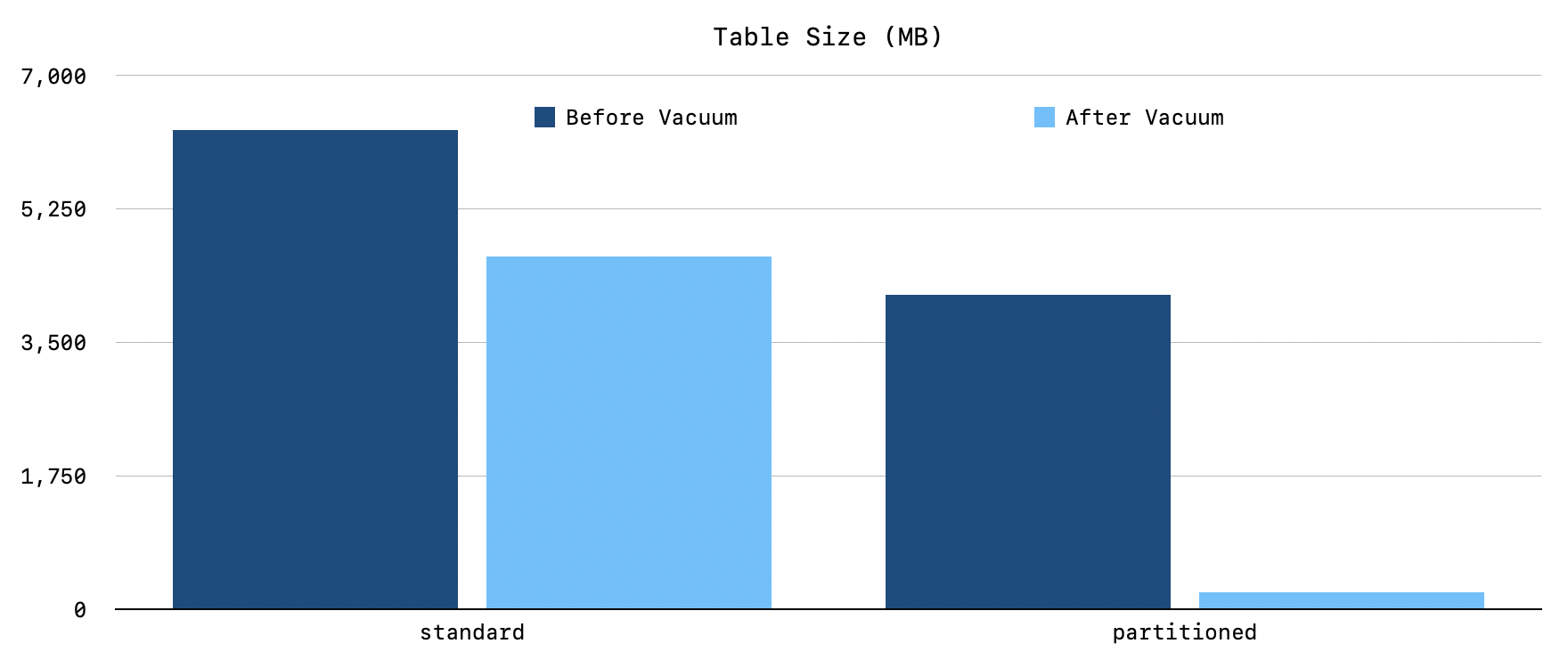
The combined tables were 40% smaller (6,281MB to 4,121MB), with 95% less bloat after vacuum (4,625MB to 230MB):
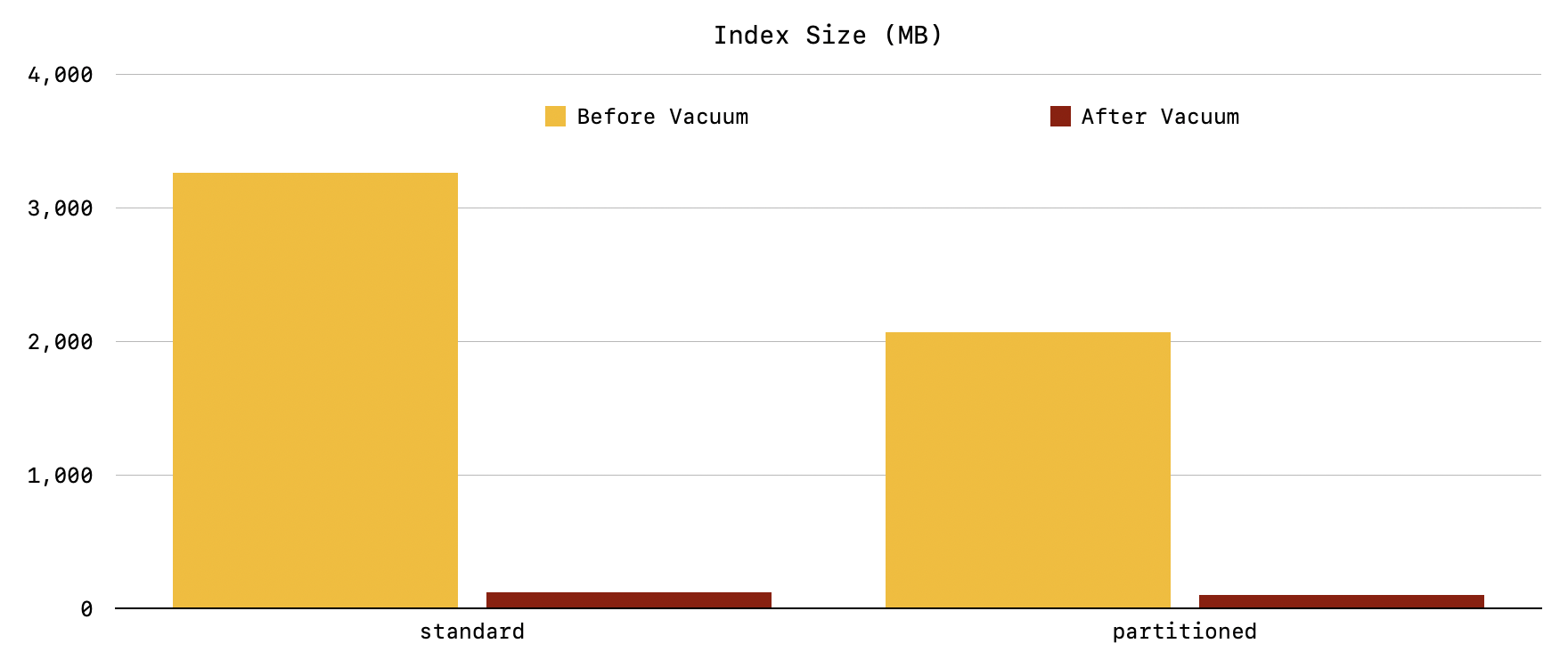
Indexes were 37% smaller before vacuum (3,265MB to 2,068MB), and 18% smaller afterwards (123MB to 101MB):
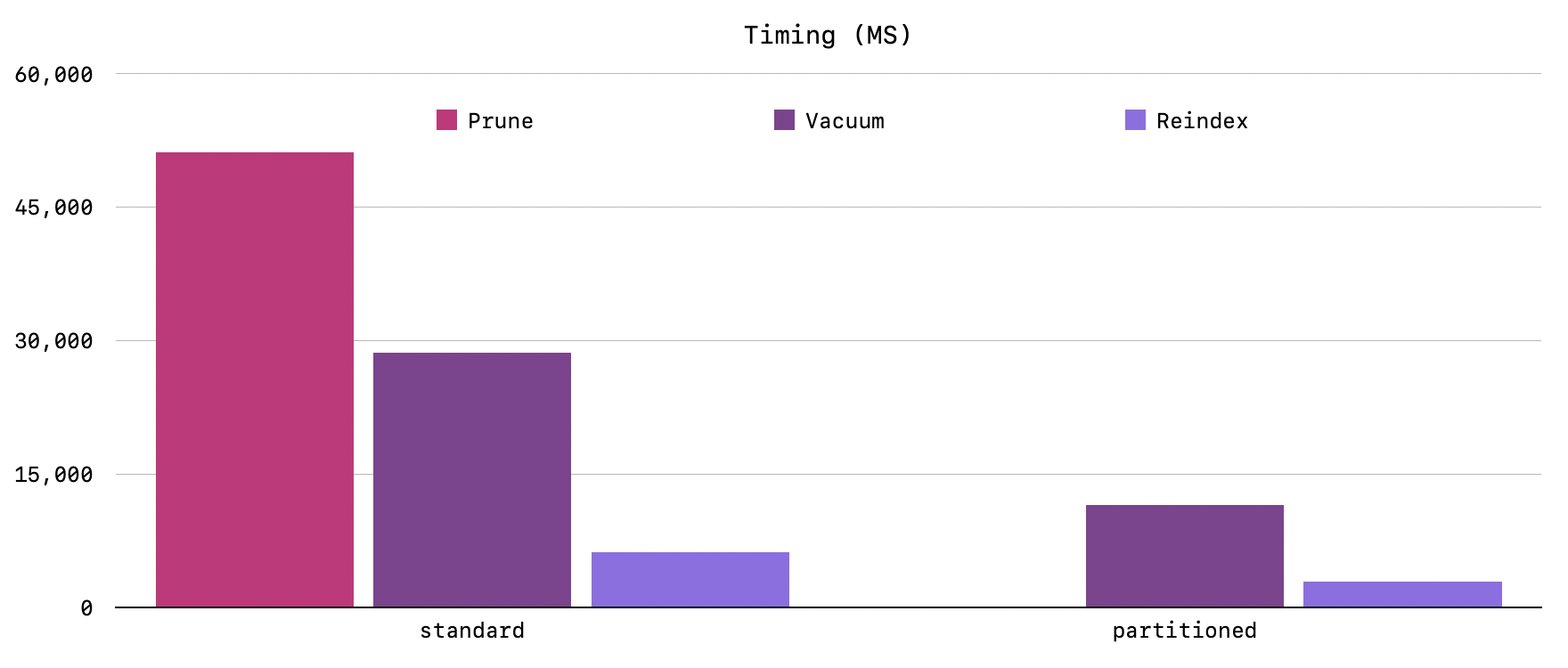
Finally, vacuuming was 2.5x faster (28,638ms to 11,529ms), reindexing was 2.1x faster (6,248ms to 2,939ms), and astoundingly, job pruning was over 1000x faster (51,170ms to 49ms). Partitioned pruning is so fast that it isn't visible in the chart:
Partitioning has evolved since Oban was released 5 years ago, when we supported Postgres versions that didn't yet offer declarative partitioning. Since then, it has matured with every release and it massively improves Oban's ability to handle high-volume workloads with minimal bloat.
Keep on Scaling
The Elixir community is flourishing and we have impressive applications running millions of Oban jobs a day. Postgres' capabilities keep growing, Elixir gets better with each release, and we strive to keep refining Oban Pro to scale along with you.
Upgrade to Pro v1.3 for a tremendous reduction in database queries, and consider switching to partitioned tables to tackle bloat for high throughput systems.
As usual, if you have any questions or comments, ask in the Elixir Forum or the #oban channel on Elixir Slack. For future announcements and insight into what we're working on next, subscribe to our newsletter.