
People frequently ask about Oban's performance characteristics, and we typically answer anecdotally—"on this one app in this one environment we run this many jobs a day and the load is around blah." That's real world usage data, but not exactly reproducible. The goal of this article is to fix that ambiguity with numbers and (some) math.
You know—and we know that you know—you're here to see some schmancy charts that back up the claim of "one million jobs a minute." Good news! We'll jump right into benchmark results and charts. Afterwards, if you're feeling adventurous, stick around to dig into the nitty-gritty of how much load Oban places on a system, how it minimizes PostgreSQL overhead, and our plans for eking out even more jobs per second.
The Benchmark
This is the story of a benchmark that demonstrates the jobs-per-second throughput that Oban is capable of. The benchmark aims to process one million jobs a minute, that's 16,1667 jobs/sec, in a single queue on a single node. Running multiple queues or multiple nodes can achieve dramatically higher throughput, but where's the fun in that?
Not to spoil the story, but it didn't take much to accomplish our goal. Oban is built on PostgreSQL, which has a stellar benchmarking story and widely documented results for write-heavy workloads, which is precisely Oban's profile.
Our benchmark inserts one million jobs and then tracks the time it takes to complete processing them all with a throughput measurement every second. (Reporting and metrics aren't shown, but you can find the original script in this gist).
# Start Oban without any queues
Oban.start_link(repo: Repo)
# Create an atomic counter and encode it to binary for use in jobs
cnt = :counters.new(1, [])
:ok = :counters.put(cnt, 1, 0)
bin_cnt =
cnt
|> :erlang.term_to_binary()
|> Base.encode64()
# Insert 1m jobs in batches of 5k to avoid parameter limitations
Task.async_stream(1..200, fn _ ->
Oban.insert_all(fn _ ->
for _ <- 1..5_000, do: CountWorker.new(%{bin_cnt: bin_cnt})
end)
end)
The CountWorker job itself simply deserializes the counter and atomically increments it:
defmodule CountWorker do
use Oban.Worker
@impl Oban.Worker
def perform(%Job{args: %{"bin_cnt" => bin_cnt}}) do
bin_cnt
|> Base.decode64!()
|> :erlang.binary_to_term()
|> :counters.add(1, 1)
end
end
Now, to process all one million jobs in a minute our queue needs to chew through at least 16,667
(⌈1,000,000 / 60⌉) jobs per second . Theoretically, if fetching and dispatching jobs was
instantaneous, and there wasn't any throttling, setting concurrency to 34 (⌈16,667 jobs / (1000 ms / 2 cooldown)⌉) would get the job done.
# Start the queue that all jobs are inserted
Oban.start_queue(queue: :default, limit: 34, dispatch_cooldown: 2)
In practice, back in reality, the limit needs to be quite a bit higher to compensate for the actual work of fetching and dispatching jobs. This chart illustrates rerunning the benchmark with increasing concurrency until it tops one million completed jobs:

The magic concurrency number, on this machine 👇, is 230. It peaks at around 17,699 jobs/sec and finishes one million jobs in 57s.
👉 Erlang/OTP 25, Elixir 1.14.0-dev, PostgreSQL 14.2, Apple M1 Pro (10 Cores), 32 GB RAM, 1TB SSD
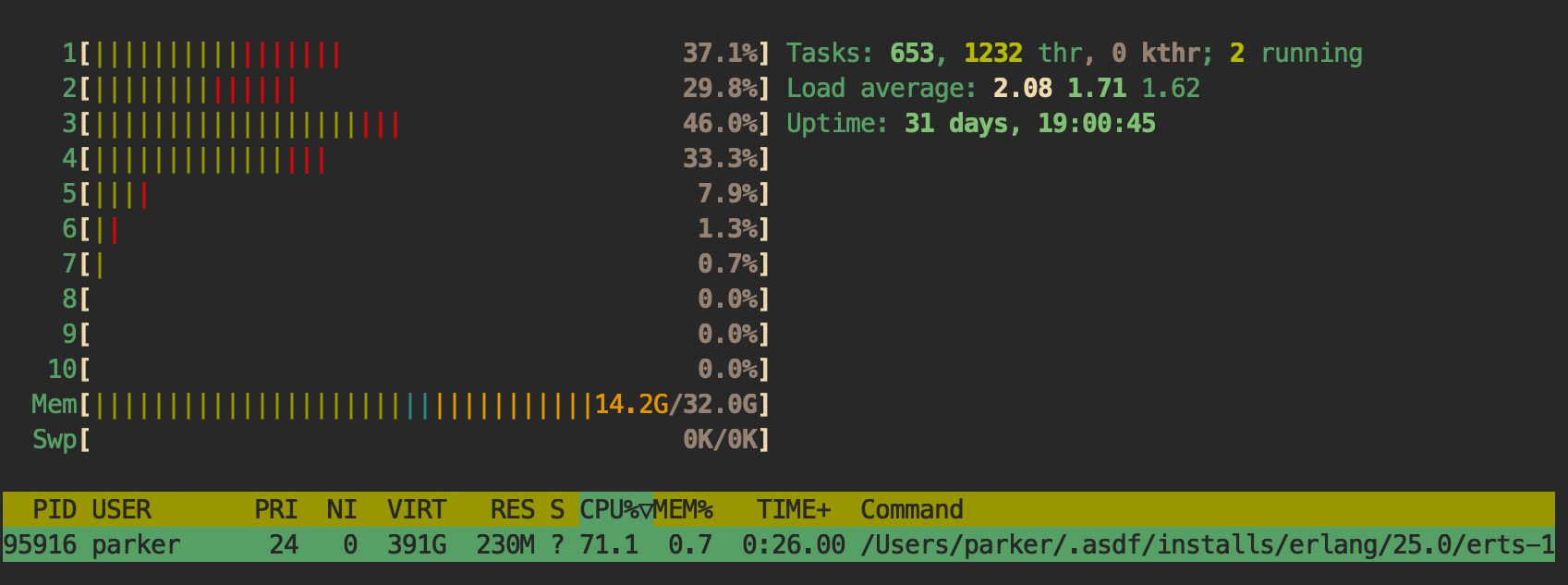
But what's the system load like, you ask? HTOP screen captures have the answer. First the single BEAM process:
And here's the Postgres load showing all 10 connections and the various daemons:
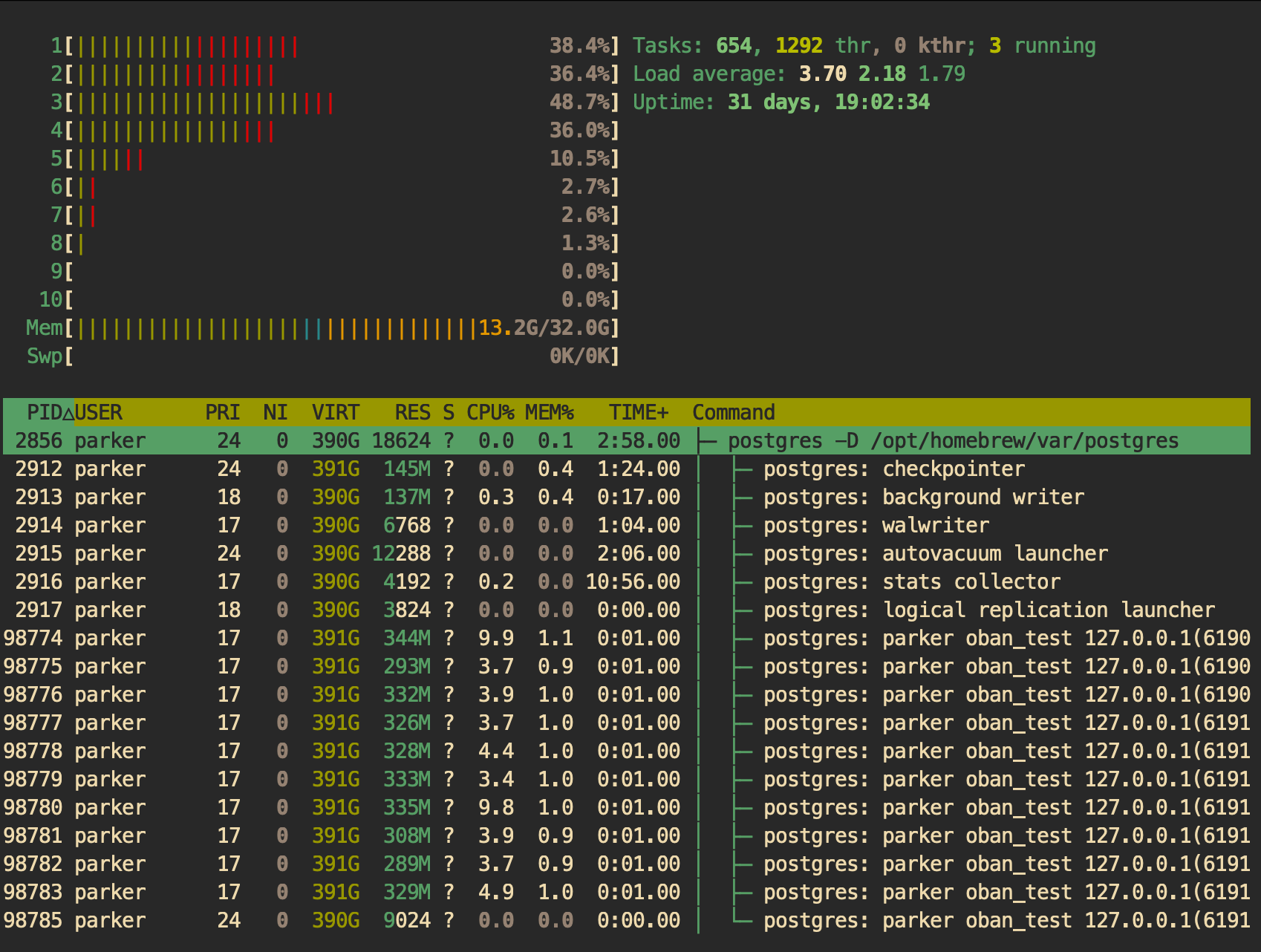
Cores 1-4 are 29%-46% engaged while the other six sit around like freeloaders with only a smattering of activity.
The Limits
Now that we know we can hit the one million jobs/min goal, why not find out how quickly we can do it?
With a single queue on a single node the only knobs we have to tweak processing speed are
concurrency (limit) and cooldown (dispatch_cooldown). Concurrency determines how many jobs
will run at once, while cooldown limits how frequently a queue fetches new jobs from the database.
The default cooldown period is 5ms, and the minimum is 1ms. Some measurement (er, trial and error) shows that a 2ms cooldown period is optimal because it strikes a balance between quick fetches and not thrashing the database. With cooldown dialed in, all that's left to explore is concurrency.
Running the benchmark again with increasing concurrency from 230-3,000 paints a telling picture:

The total time to complete 1m jobs decreases steadily until it bottoms out at around 2,000 concurrently. After that point fetching slows down, the BEAM gets overloaded, and overall processing time starts to rise. But, when concurrency is set to 2,000 it completes in 30 seconds—that's two million jobs a minute.
The benchmark also tracks the average jobs per second over time. If we dig out the peak jobs/sec for at each concurrency limit we get this companion chart:

Throughput tops out around 32,000 jobs/sec, over two billion jobs/day, and well beyond the realm of reason for a single queue. Real jobs do real work in an application, and that's where the real load comes from.
The Not-So Secret Sauce
There's a little extra sauce at work to reach such high throughput when concurrency is set at 2,000. Beyond Oban's core historic sauce—index-only scans for fetching, a single compound index, debounced fetching via cooldown—two new changes unlocked substantial performance gains.
Async Acking
While job fetching is optimized into a single query, "acking" when a job is complete requires a separate query for every job. That puts a lot of contention on the shared database pool and the associated PostgreSQL connections. Or at least it did, before the addition of an async acking option. Async acking trades consistency guarantees for throughput by batching calls together and flushing them with a single database call. The reduction in pool contention and database calls increases throughput by 200-210%.
Partitioned Supervisor
Perhaps you noticed earlier that the benchmarks are running with Elixir 1.14.0-dev? That's to make
use of the unreleased (as of this post) PartitionSupervisor. Without partitioning, the
Task.Supervisor that supervises all of the job processes is a bottleneck. Swapping in the
PartitionSupervisor spins up one supervisor for each core and increases throughput 5-10%,
virtually for free.
Neither of these changes are released or on main yet, but watch for a variant of them in the future.
The End
Oban's primary goals may be reliability, consistency, and observability, but we strive to keep it as speedy as possible. If Oban is your application's performance bottleneck, it should either be because your business is booming (congratulations 🎉), or there are insidious bugs at play (we have work to do 😓)!
As usual, if you have any questions or comments, ask in the Elixir Forum or the #oban channel on Elixir Slack. For future announcements and insight into what we're working on next, subscribe to our newsletter.